DeepLearning 찍먹
머신러닝과 딥러닝 차이
머신러닝: 사람이 가이드를 제시하고 그 위에서 알고리즘을 찾음.
딥러닝: 다량의 데이터 속에서 ai가 규칙을 찾아냄. 뉴런네트워크를 이용해서 머신러닝을 진행함.
> 내가 수학 능력이 부족해도 ai만들기 가능(약간은 필요)
딥러닝은 이미지 판별(자율주행), 순서 추론(번역)에서 특히 강함.
머신러닝의 종류
1. supervised learning: 정답이 있는 경우, 정답 데이터를 분석하나?
2. unsupervised learning: 정답이 정해지지 않음 > 데이터를 군집화함
3. reinforcement learning: 수없이 반복하여 점수를 높이를 방향으로 알고리즘을 바꿈.
w1, w2 ... : 예측하는 변수
h1, h2 ...(히든 레이어) : 각 레이어에서의 값
layer= 학습 진행 단계
딥러닝은 각 단계에서의 현재 값과 가중치를 곱하고 다음 레이어에서 모인 값을 모두 더한 값을 현재값으로 사용하여 이를 반복함.
결국 최종 합을 구하는데 최종 값이 예측값이고, 실제값과 비교하여 오차를 구한다.
중간에 히든 레이어를 많이두면 변수가 많아지고 정밀도가 높아진다.
학습을 할 때 임의의 가중치에 대해 수 많은 데이터를 넣어가며 평균 오차를 구하고 가중치를 바꿔가며 오차가 가장 적은 가중치를 구한다.
그러나 히든레이어를 추가해도 결국 단순 1차 변수의 곱으로 치환이 가능해진다. >> 계산만 복잡해지고 정확도가 높아지지 않는다. + 선형적인 단순한 예측이 된다.
ex) n1*w1 + n2*w2 + n3*w3 ...
따라서 활성함수(계산식에 선형적이지 않은 계산)을 추가하여 정확도를 높인다. + 비선형적인 예측
활성함수의 예시로는
1. sigmoid

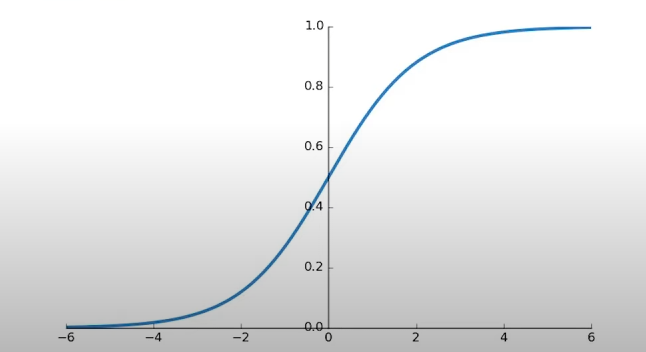
2. Hyperbolic tangent


3. Rectified Linear Units


이러한 함수를 히든 레이어에 추가하여
히든 레이어에서의 값을 함수의 x에 넣고, 함수의 결과를 다시 히든 레이어의 결과로 사용하여 비선형적인 예측을 가능하게 한다.
활성함수는 모든 레이어에 있는 것이 좋지만 마지막 레이어에는 없어도 된다.
Loss (오차 E) 구하는 방법

w(가중치) 값에 따라 E의 값이 달라질텐데, E는 그래프의 형태를 띈다.
이 그래프에서 y값(오차,E)가 최소가 되는 위치를 찾는 방법은?
경사하강법을 사용한다.
: 그래프의 기울기가 아래로 볼록한 지점을 찾는다. / 그래프를 타고 값이 줄어드는 방향으로 접근하여 기울기가 0이 되는 곳에서 멈춘다.
> 아래로 볼록한 지점을 찾았지만 아래로 볼록인 지점이 여러 곳인 경우 최소값의 위치가 아닌 변곡점에서 정지함.
> local minima

>> learning rate를 사용하여 랜덤성을 증폭시킨다. learning rate optimizer를 통해 기울기가 0인 점을 찾는다,
보통 learning rate optimizer는 여러 종류가 있는데 보통 Adam 을 많이 사용한다.

https://www.youtube.com/@codingapple
코딩애플
여고생입니다
www.youtube.com